

I Can’t Keep Asking If It’s AI or Not
Inside the Content Crisis and the Fight to Restore Trust Online

In what feels like a relatively short period of time, the internet has become an incoherent mess. It is now increasingly unclear what content is real, what is AI, and everything in between. I wrote about an aspect of this back in April, as I was concerned about our collective, rapid inability to distinguish between types of content online. It is clear that now, in November of 2025, this problem has only gotten worse.
The release of Nano Banana Pro on November 20th has proven to be a watershed moment, with the internet collectively losing its mind over the model’s diffusion capabilities. Simply put, NBP has blown previous image diffusion models out of the water. Images can be quickly generated that are so realistic, it is virtually impossible with the naked eye to tell that the image is AI-generated.

We all knew this moment would come, but it was never entirely clear what would happen next. Even with video lagging behind, every image seen online must now be met with skepticism. Is this AI? Is what I’m looking at real, or fake?
In this article I’m going to cover where we’re at with digital watermarking and content provenance, what organizations and governments are making key decisions about the future of the internet, and what to expect in the future. There are many factors at play, but it is truly worth understanding. The landscape is complex, but understanding this is crucial for living and working within the new internet.
Let’s dive in.
The Content Crisis in 2025
Make no mistake, 2025 is the year that we collectively realized there was no longer a clear distinction for what was human versus machine made online. The old trust models have died. As many of you remember, it wasn’t too long ago that a video or photograph was near proof of something being genuine. We’d say ‘Show me a video!’ and that was all we needed. Sure, things could be faked, but it often required time and skill to look believable.
Those days are over.
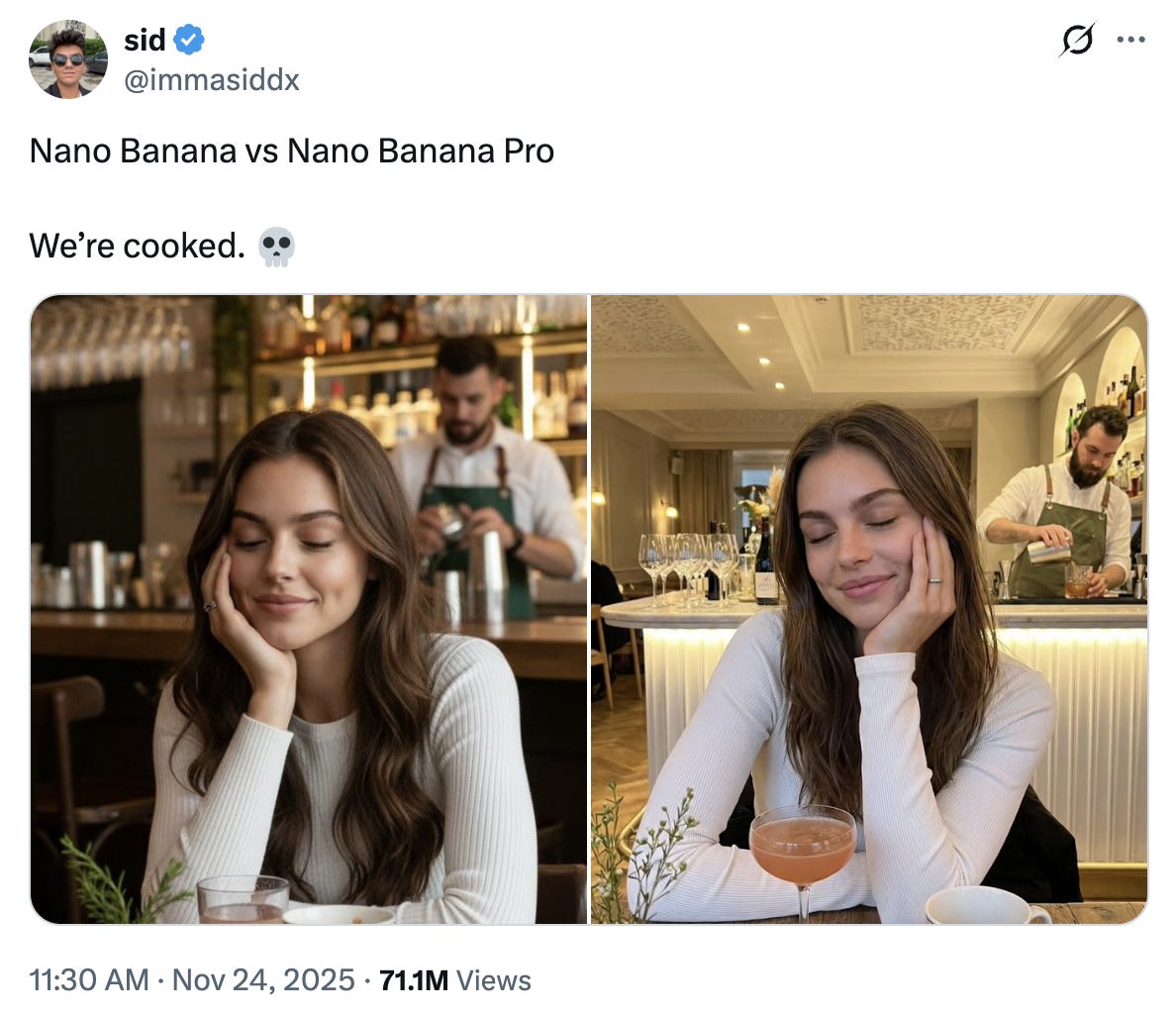
Once AI content is truly indistinguishable from real content, what is ‘real’ can be just as equally dismissed as fake. Evidence can be generated, and activity on online platforms can be mimicked and emulated by bots. We’re existing in a liminal space, one where new AI paradigms and the old ways of using the web co-exist in complete chaos. Everything from profile pictures to real-time video calls can be spoofed. AI-generated audio has become believable enough that I personally can no longer tell the difference.
Now, surely, something’s got to give. The tools and programs used to spoof everything will only get better, and it won’t be long before the successor to Sora is generating videos so lifelike, you’d swear they were real. With video diffusion models trained on all of YouTube, the most viral content will no longer be human-made, it will be AI-generated snippets designed from the ground-up for maximal engagement. When attention is the only game in town, you either adapt or die. Mid-tier human content won’t go viral, AI content will.
Guessing, or using detection models while browsing the web and interacting with content is not the solution. Detection models often produce false positives, which can lead to labeling human-created content as AI. This is bad, and leads to a further erosion of trust online.
The solution to understanding what we’re seeing and watching online is not retrospective guessing. The solution is structured metadata and embedded cryptographic proofs at the moment of creation. I’m talking about content provenance.
The Content Provenance Landscape

Although the content provenance space has been evolving for the last 6 years, most people are unfamiliar with it and the various organizations and companies leading the charge.
To start, what is content provenance?
Content provenance - the recorded and verifiable history of a piece of digital content, such as an image, video, audio file, or document.
In February of 2021, Microsoft, Adobe, and others got together and co-founded the Coalition for Content Provenance and Authenticity (C2PA). C2PA’s goal is to push forward a royalty-free technical standard in the fight against disinformation. The Content Authenticity Initiative (CAI) is a related association that has the goal of promoting this new standard.
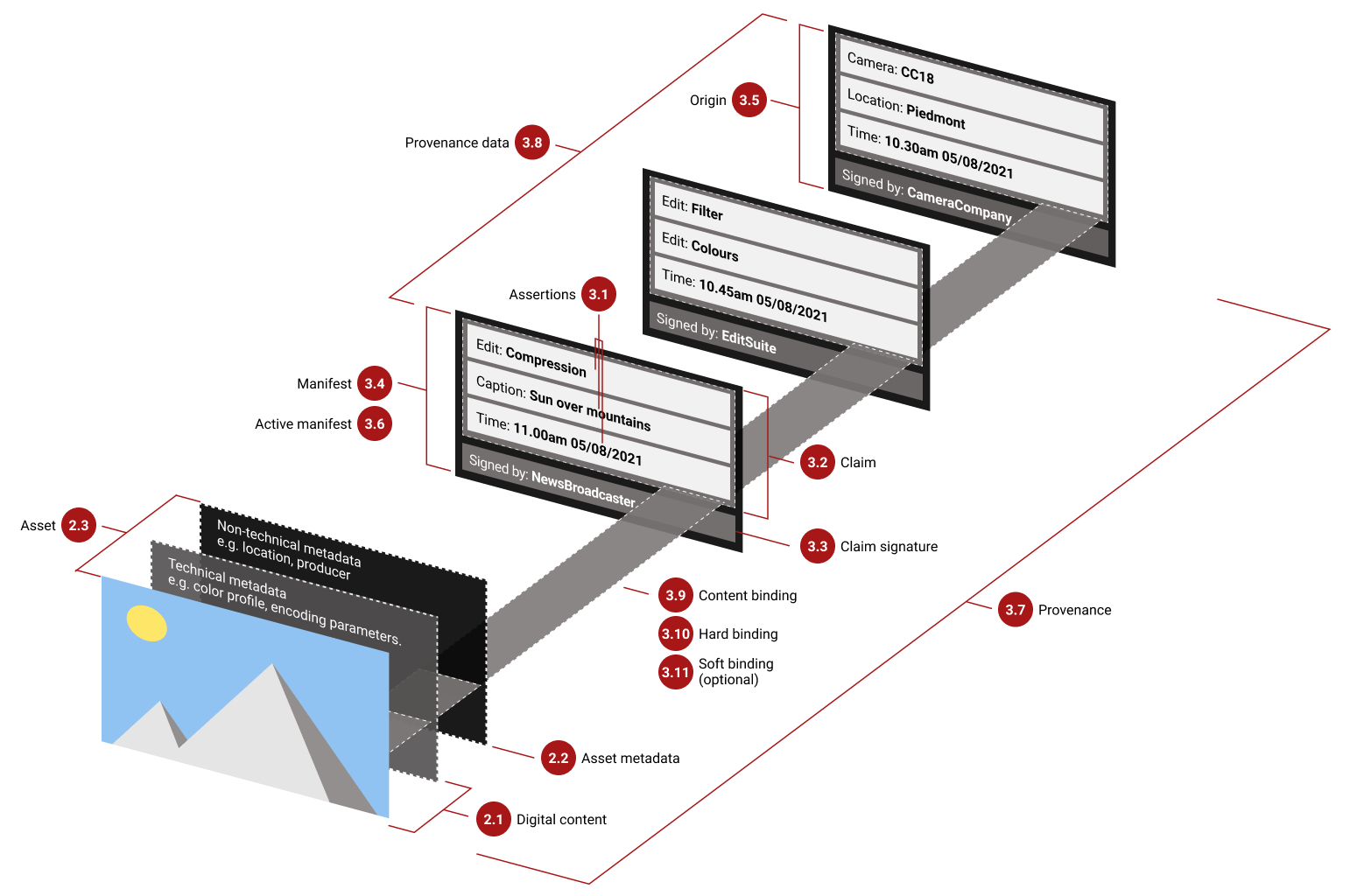
Every C2PA-enabled file contains a Manifest, a container of assertions with statements like ‘Edited by Adobe Photoshop’ or ‘Generated by Sora’. These manifests are stored inside the files using a structure called JUMBF, which simply adds a metadata container to the file.
Assertions made are signed using a private key utilizing PKI, ensuring that the files are only cryptographically signed by valid signers (it cannot be spoofed). Ideally, you’ll see a C2PA-signed image or document accompanied by a small “CR” icon, and clicking on it will reveal that file’s origin, who signed it, and what edits have been made.
The final result is a potential ecosystem where all media content has digital provenance metadata attached to it, so you can clearly see how something was made, how it was edited, and verify the source.
As long as the metadata stays intact, we’re good. Unless, of course, it gets stripped.
The Stripping Problem
C2PA metadata is great, but there are a number of problems with relying on it exclusively. Currently, most social platforms scrub metadata when you upload a file. If you upload an image to Instagram, the platform automatically removes EXIF, IPTC, and XMP metadata to reduce file size and prevent unwanted data from leaking (like GPS coordinates showing where you took the photo).
Largely, this is a good thing, but platforms haven’t yet evolved to retain critical provenance data, if it exists at all. C2PA is vulnerable to social-media compression and re-encoding, screenshotting, and various image optimization pipelines. Even though many organizations have already adopted C2PA, end users rarely see its usage in the wild. At best, we’re relying on community notes on X, generic AI banners, or (in the case of most platforms) no information at all.
Surely there’s a solution to the stripping problem, right?
SynthID and Invisible Watermarking

Google’s SynthID steps in where C2PA metadata falters. SynthID is invisible watermarking; the watermark is embedded into images and videos and is robust enough to survive compression, some editing, and screenshotting. It isn’t visible to the human eye, but detectable by authorized systems.
Even this isn’t perfect. SynthID can be broken with generative in-painting, aggressive editing, and using deep learning models to create advanced noise-based transformations. That said, SynthID survives where C2PA metadata doesn’t.
The Hybrid Approach
When combined, C2PA and SynthID are a formidable combo in the fight for increased transparency online:
C2PA holds the provenance record, with details on edits and origin
SynthID embeds an invisible signal into the image that persists even if the metadata is stripped by an organization or bad actor
The SynthID watermark can contain an ID that can be used to lookup the original C2PA manifest, ensuring information stays intact.
Together, this is what we’re working with at the end of 2025. It isn’t perfect, but it’s better than nothing.
Our Broken Digital Content Flow Today
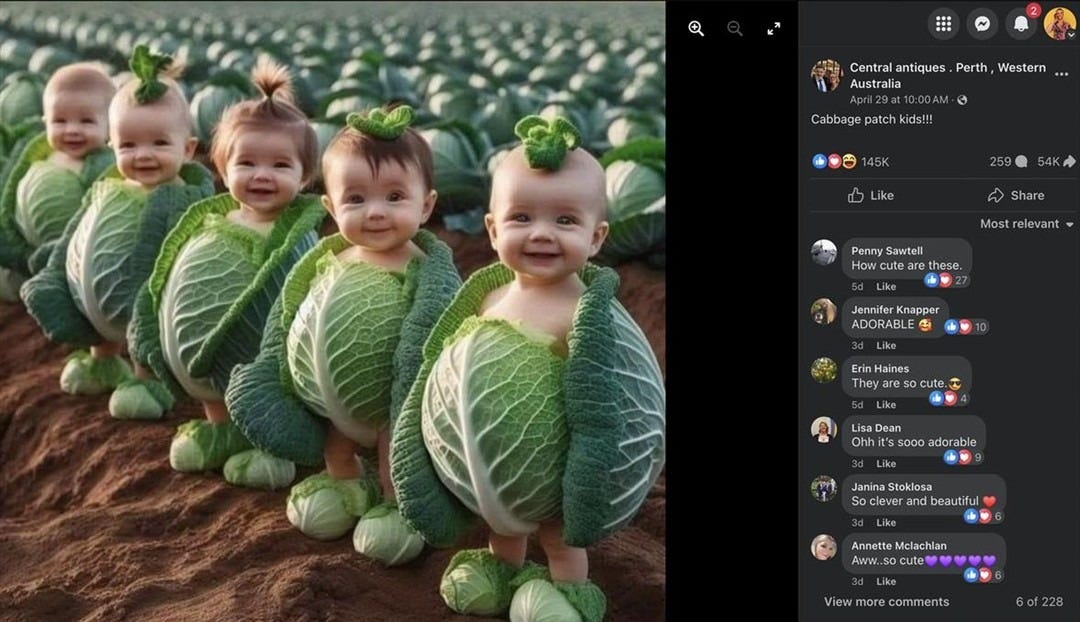
Take a look at the above image. This is a screenshot from Facebook earlier this year. You’ll quickly notice that there is zero indication that this content is AI-generated. The unassuming readers are none the wiser, with many earnestly believing what they’re seeing is real.
Today, if you scroll through most social platforms, you will not be met with clear banners or prefaces indicating that content is AI. At best, you may encounter top comments or community notes on X that indicate that something is AI, but this is almost always in response to uploaded content, and not done proactively. Surprisingly, TikTok has been the most proactive as a major social network, becoming one of the first video sharing network to implement C2PA.
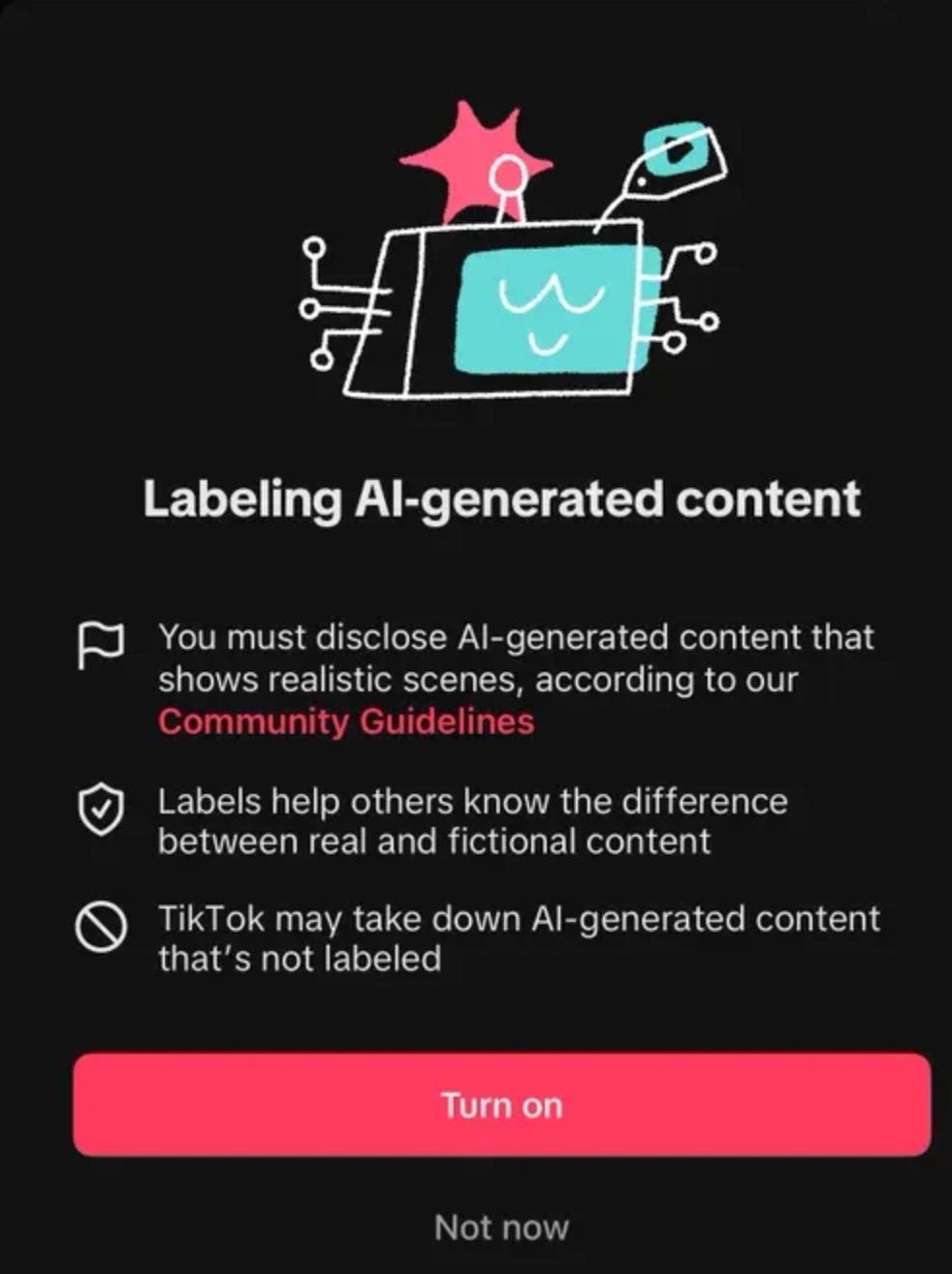
Because platforms deal with massive amounts of uploaded data daily, they are constantly compressing and reprocessing content. Metadata is stripped, so even if C2PA is provided, it rarely makes it to where it matters: actual people. Shockingly, all major web browsers lack native support for displaying provenance, and the distribution layer for content hasn’t been updated. The pipes have been laid down, but there’s no faucet.
The Ideal Flow
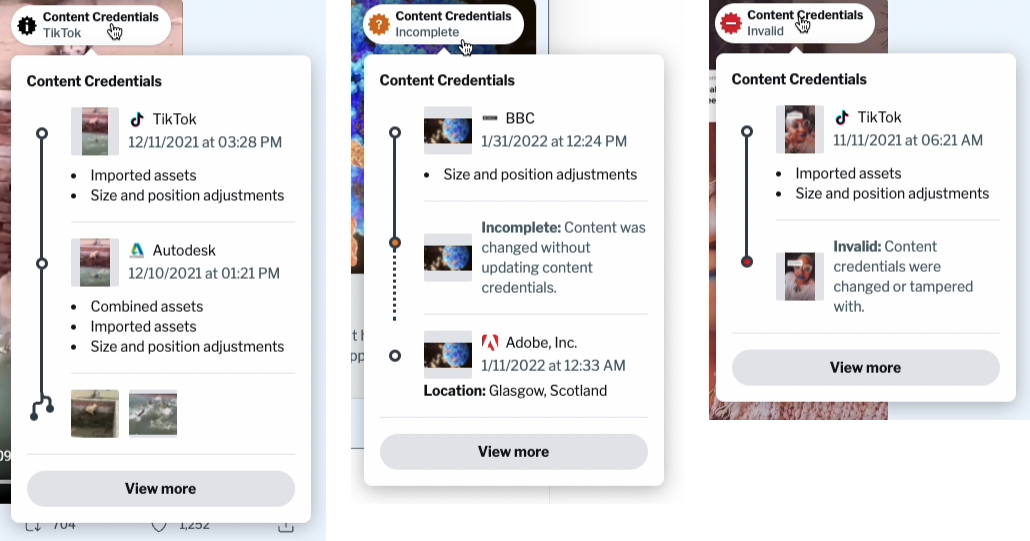
AI-content makes everything more complicated online. We really only have a couple of options: limit AI-content to AI-exclusive platforms, or add content notes and banners to spaces where human and AI content co-mingle. Of course, even if you tag all of the content on a platform, users will still constantly wonder what the content actually is, and where it came from.
The ideal flow for a social network with content ranging from human to AI-generated looks like this:
You log in, scroll, and start discovering content
At the top right of every piece of content, a checkmark shows its status. This checkmark is colored, and indicates if the content’s credentials are valid. Additional marks for fully or partially AI-generated content are visible and present.
If you’re interested, you can click on the content checkmark and see additional information. Everything from how it was created to when it was modified is available.
Eventually, content that has no credentials may not even be allowed to be uploaded to the platform. Users will, inevitably, begin to prefer content that is considered legit, and has the proper checkmark(s). AI content will come with its own biases, and many spaces will become human-only (this is already happening).
This might sound like an exhausting and tedious extra layer for interacting with the internet, and that’s because it is! AI introduces a host of new concerns online, and the origin of media is one of them. Robust measures to ensure AI stays out of human-only spaces will be an ongoing struggle, and one that is already proving incredibly difficult.
Regulations and Unwatermarking

When the EU passes new mandates, they often become de facto global standards. Decisions surrounding GenAI are no exception to this rule. With the passing of the EU AI Act, machine-readable watermarking and provenance for generative AI content is mandatory in the EU. In America, California attempted to pass AB 3211 in 2024, which would have required many social media providers to have re-engineered media ingestion pipelines.
With Europe moving forward with watermarking, the rest of the world will most likely adopt this standard. However, there are numerous workarounds for ‘unwatermarking’, which is exactly what it sounds like, removing visual watermarks and provenance signals.
Getting around text watermarking is easy. For images, local models (like FLUX or Stable Diffusion) generate images without watermarks. Scripts can be used to strip C2PA metadata, and generative in-painting can be used to remove SynthID. The tools for removing content info will only get more sophisticated, and not everyone online is completely aligned with C2PA’s approach to applying metadata.
The Future

The internet is evolving. Like many people, I have a certain nostalgia for the internet of the past. I miss the simplicity of the early 2000s web, and I’ve realized that I’ll likely soon have similar nostalgia for the web pre-AI.
Every deepfake will not be detected. Every AI image will not be tagged. We’ll need to work together to make an internet that we actually want to use. The old trust models are dead, and now we’re building the new ones. Everything feels weird and off, and it’s okay. We’ll figure it out.
I’m convinced that platforms will need to adapt quickly as AI progresses. Our sanity depends on it.
Thanks for reading.
- Chris
Great post. I think about those broken trust models very often and the pressure now on humans to prove we are not machines. I appreciated your note of optimism at the end.