
Diffusion is Eating the World
Text was the last holdout

A shift is happening in generative AI. We’ve gone from ‘is it smart enough’ to ‘can it be fast, smart, accurate, and affordable?’ Can we make useful AI that is also fast? Conversations have shifted from being defensive, focused on alignment and reason, to economics. Can this model run fast enough to power real-time agents? Can I embed it into everyday interactions? Can I run it locally on my computer? In late February of 2026, the answer is yes, yes, yes.
The Typewriter Analogy

Inception Labs made headlines this week by launching Mercury 2, touted as the world’s fastest reasoning language model. It’s a diffusion-based language model, a dLLM, and its release is the result of years of research. Inception first released Mercury exactly a year ago today, and Mercury 2 is an upgrade in every regard.
Major language models today are autoregressive (AR), and every major model you’ve interacted with operates on the same principle: generating one token at a time, from left to right, with each new token conditioned on everything that came before it. AR decoding works well, but it is the reason why text generation can often feel sluggish.
The typewriter analogy works well here. Each character gets stamped onto the page, one at a time, permanently and in order. If you make a mistake, every character that follows is influenced by that mistake. There’s no mechanism to go back and revise. This is how single-shot works.

This was an acceptable tradeoff when AI interactions were mostly single-shot, but things have changed substantially in the last couple of years. Between reasoning models, executing tools, and calling MCPs, the typewriter bottleneck begins to compound. There are ways to speed up the typewriter, (like speculative decoding, which speeds things up a lot), but the fundamentals remain the same.
It’s still a typewriter, and today’s frontier models are incredibly smart, but slow.
Diffusion, Diffusion, Diffusion
Diffusion is a paradigm that is winning out in every other generative modality. Now, finally in 2026, it is beginning to come for text, the very last holdout.
Diffusion became the primary approach for imagery generation in 2022, with Stable Diffusion, DALL-E, and Midjourney. It is the unquestioned standard in image generation. Video is proving to be no exception to this rule: diffusion has surpassed generative adversarial networks (GANs) and AR in terms of quality and adoption. Every major genAI video product uses it.

This month, Bytedance’s Seedance 2.0 went viral, which utilizes a dual-branch diffusion transformer to generate coherent, multi-shot synchronized audio-video sequences. The bar was raised overnight for quality expectations for video diffused content, with plenty of people saying on X that ‘Hollywood is Cooked’.
Diffusion has won within the realms of images and video, and it is also a major component for platforms like Suno for audio diffusion. Suno’s architecture is a hybrid: AR transformers handle musical structure, while diffusion models handle fidelity, transforming sequential outputs into higher studio-quality sound. AR figures things out, and the diffusion layer makes it sound incredible.
Diffusion fundamentally works the same across all mediums: you start with noise, and iteratively refine towards signal through parallel denoising. For a product like Mercury 2, text benefits from logical and structural coherence, especially the kind required for code, structured data, and multi-step reasoning.

The process isn’t like a typewriter. Diffusion models start with a complete but noisy sketch of an entire output, and refine it across multiple passes. Every token attends to both the past and future context of the sequence simultaneously, converging on the final results. The process is similar for images, video, audio, and text.
Diffusion changes a few things:
Latency becomes decoupled from output length. You pay a fixed cost for refinement steps, regardless of how many tokens you’re generating
Errors can be corrected mid-generation natively, no additional inference passes required
Structured outputs like code can become more reliable because the model has global context during generation. Self-adaptive scaffolding frameworks help with structural adherence
Compared to using AR, you can stop the generation at any point and get a result
There’s a lot to be excited about when it comes to dLLMs. With their ability to do mid-generation adaptation, that opens the door for real-time model adaptation; models can improve continuously and have some form of self-evolution. Having a model that could train and improve automatically based on user feedback would be an improvement over how we’re currently using AR-based models today. If you really want to dig into diffusion models, I highly recommend Devansh’s article here.
Mercury 2: The Commercial Leap
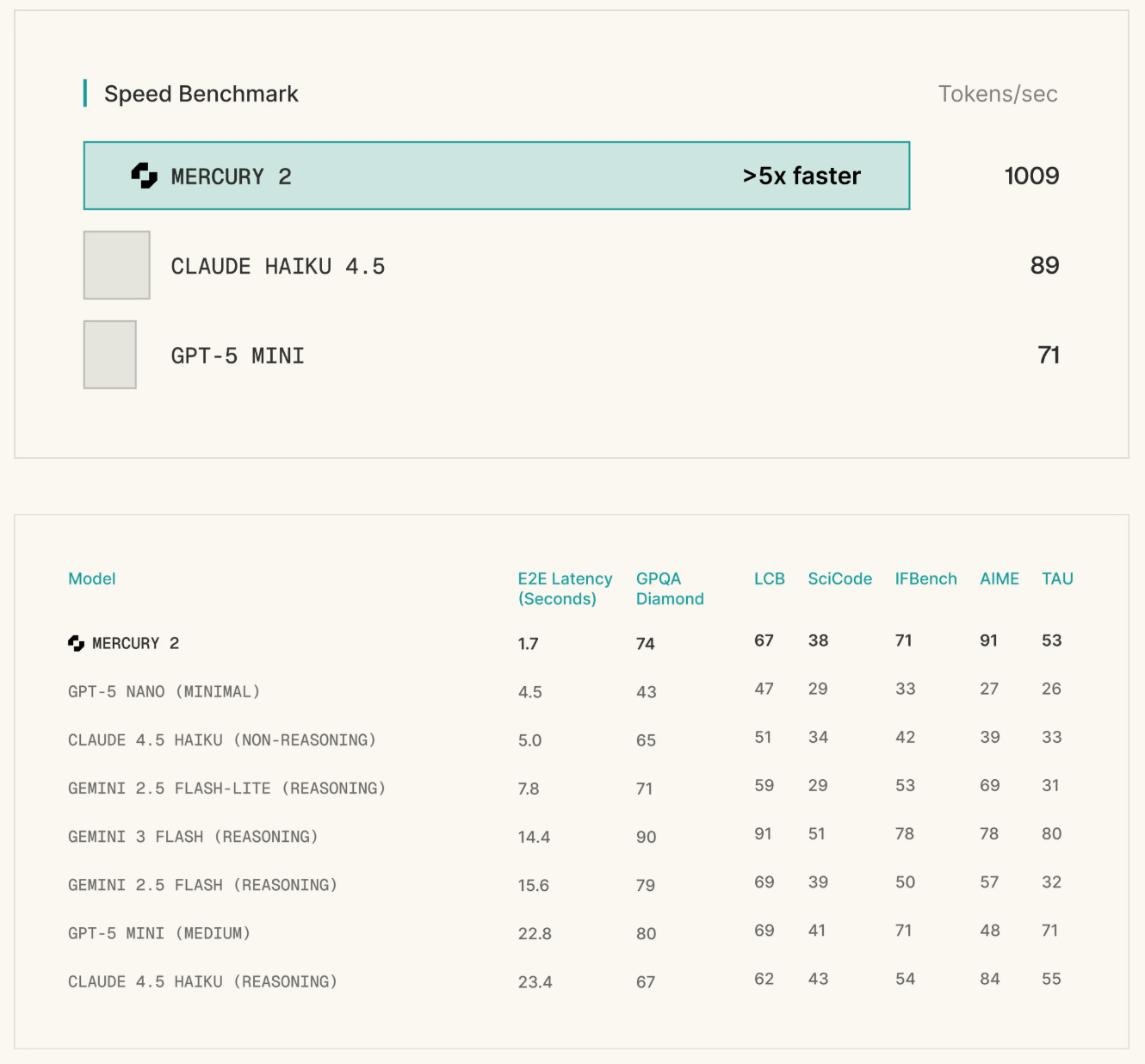
Mercury 2, built by Inception Labs, is not being touted as the smartest model. It isn’t. It is being positioned as the model that makes agents, voice, and search work in real-time at production scale.
Mercury 2 charges $0.75 per million output tokens (compare that to OpenAI’s GPT 5.2 at $10.00 per million). That’s a 13x gap. Compared to other frontier companies’ smaller models, the gap is remarkable; Mercury 2 is smarter and faster than leading frontier flash and mini models (like Haiku, Gemini 3 Flash, etc). If you are reading this, seriously consider trying out the demo on their site.
When Mercury is embedded into an autocomplete experience, users describe it as feeling like a part of their own thinking, rather than something you have to wait for. Response times happen at the speed of your thought. Smaller text diffusion models will likely become the go-to for real-time transcript cleanups.
A huge current bottleneck with agents (especially you OpenClaw users out there) is the latency between the request and the response from the agent. Personally, I’m running Kimi K2.5 on my claw, and it still feels too slow. Mercury could be a decent balance between speed and intelligence. Mercury exposes an explicit reasoning effort parameter with values ranging from instant to high (plus an optional reasoning summary), which means you can dynamically trade speed for depth within a single API. That’s huge.
With Microsoft, NVIDIA, Snowflake Ventures, and Databricks actively investing into Inception, it’s clear that this isn’t just a fun experiment anymore, it is where a lot of people think production AI is heading. NVIDIA has had an interest in this for a while, and authored a paper last year on dLLMs.
The Cost Collapse
Diffusion models are expensive to run, and compute intensive. But, like with traditional AR, the costs are dropping rapidly.
A common argument about running AI models is that they’re simply too expensive to justify running, or that they use up too much electricity and will never be efficient. This simply isn’t the whole story.
For example, the cost of achieving GPT 3.5-level performance dropped over 280x between November 2022 and October 2024. GPT-4 equivalent performance today now costs ~$0.40 per million tokens, versus $20.00 in early 2023. This is a 50x reduction.
Plenty of models, like Qwen 3.5, are smart enough for many tasks that companies were previously using frontier models for. Open source agent frameworks paired with running your own compute network rapidly reduces costs.

If you’re processing 10,000 customer support tickets averaging 3.5k tokens each, using a frontier model like GPT 5.2 Pro costs $1,300. Switching to a new open source model drops that cost to roughly $7, a 190x cost reduction for comparable quality on routine tasks.
These dramatic price drops apply to non-reasoning AR models, while pricing for frontier reasoning models has remained stable. If you need the best reasoning possible, you’re still going to either need to shell out cash or run something locally.
The trend is clear: good enough intelligence is getting cheap, fast, and running powerful models locally is increasingly doable with the right hardware.
A developer or privacy-conscious organization with a $2,000 consumer GPU can now run a model comparable to many frontier API offerings locally, with no data ever leaving their machine. With models like Qwen 3.5-397B that can be run locally (approaching the capabilities of frontier models like Opus 4.5) it is clear we’re rapidly approaching an inflection point. Soon, frontier-level coding capabilities can be run at your house, and all you need is a Mac Studio.
People have ranted about this to death on X for the last couple of months, but one thing is true: running frontier-level coding models locally would have been laughable two years ago. Now it’s a $2,000 GPU and a weekend of setup.
Diffusion accelerates this further. Parallel generation means longer outputs don’t carry the same linear cost penalty that sequential models do.
Counterpoints

Diffusion isn’t perfect. It’s commercially viable but there are genuine limitations worth acknowledging.
The reasoning gap is real. Gemini Diffusion scores 40.4% on GPQA Diamond versus 56.5% for its AR counterpart. You’re trading intelligence ceiling for speed.
Output length is a constraint. Diffusion LLMs often require predefined generation length. Too short and quality collapses. Too long and you waste compute.
The tooling ecosystem barely exists. AR has years of fine-tuning pipelines, quantization tools, and community knowledge. Diffusion for text is starting from near zero.
Standard caching doesn’t work. AR’s KV-cache trick breaks with bidirectional attention. Long-context diffusion inference is less optimized as a result.
Speed isn’t free. Reaching AR-equivalent accuracy sometimes requires enough refinement steps to negate the speed advantage entirely. Speed and quality are still on a slider.
In many ways, it feels like we’re starting all over again with text diffusion models. If I had to guess, we’ll likely live in a world with AR-based models for heavy reasoning and diffusion-based models for quick results.
Our Future

When intelligence is fast, cheap, local, and structurally more reliable, entirely new possibilities for applications open up. It is no coincidence that the agentic revolution, which we’ve been talking about for years, is finally happening now. Intelligence, cost, and speed are finally at a point where it is all coming together.
Diffusion is already the engine behind AI image generation, video generation, and audio. Text was the last holdout. With Mercury 2 and models like it, that holdout is ending. The race to build the smartest model is table stakes now. What matters next is making intelligence invisible, fast enough and cheap enough that you stop noticing it’s there at all.
Thanks for reading.
- Chris
lfg
I live just around the corner from Gōtokuji. Your 'hood, too?